
字节跳动
参考:https://www.nowcoder.com/discuss/98693
校招第一批笔试
世界杯开幕式
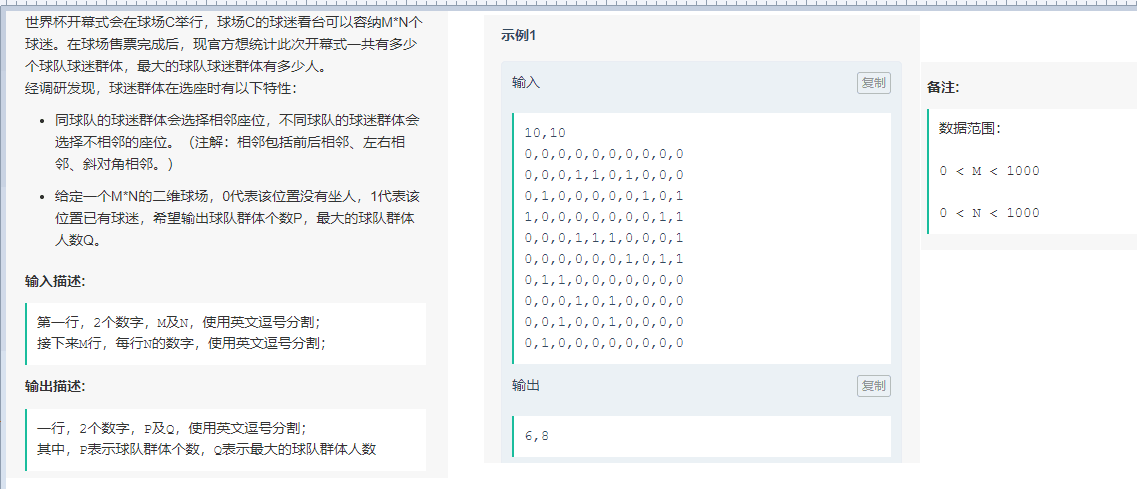
思路
深度优先搜索,这题与leetcode两题的区别在于,这题算上了斜对角,虽然学会leetcode200后,基本这类题目都能做出来,但是感觉还是要调试好久,尤其是要计算最大面积/最大球队群体人数。
代码
1 | class Solution(): |
参考:
leetcode200. 岛屿的个数
https://leetcode-cn.com/problems/number-of-islands/
leetcode695. 岛屿的最大面积
https://leetcode-cn.com/problems/max-area-of-island/
文章病句标识

思路
最关键在于先对所有区间进行排序,再对排序后的区间列表进行遍历,有交叉的区间进行合并操作,反之则添加进最终列表,思路与Leetcode56一模一样,只是换了一个题目背景。
代码
1 | import sys |
参考:
leetcode56. 合并区间
https://leetcode-cn.com/problems/merge-intervals/
团队积分
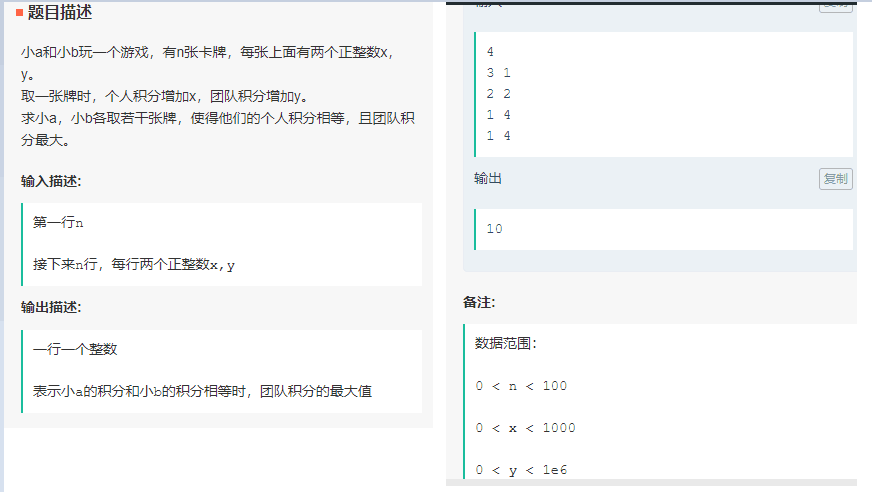
思路
背包问题的变种,很难理解,除了经典的01背包问题较好理解,其他各种变型都不太好理解,需要花整段时间去好好研究下《背包九讲》。
代码
1 | import sys |
参考:
Leetcode416. 分割等和子集
https://leetcode-cn.com/problems/partition-equal-subset-sum/
Leetcode322. 零钱兑换
https://leetcode-cn.com/problems/coin-change/
Leetcode377. 组合总和 Ⅳ
https://leetcode-cn.com/problems/combination-sum-iv/
Leetcode474. 一和零
https://leetcode-cn.com/problems/ones-and-zeroes/
Leetcode139. 单词拆分
https://leetcode-cn.com/problems/word-break/
Leetcode494. 目标和
https://leetcode-cn.com/problems/target-sum/
序列区间
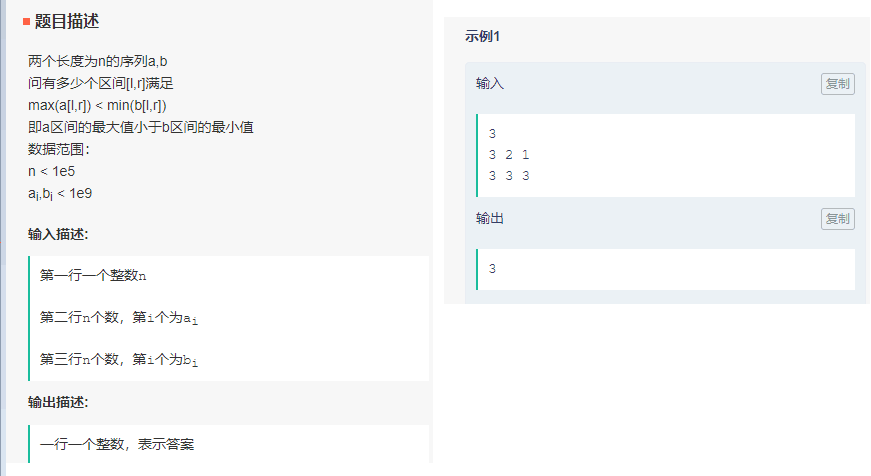
抖音主播
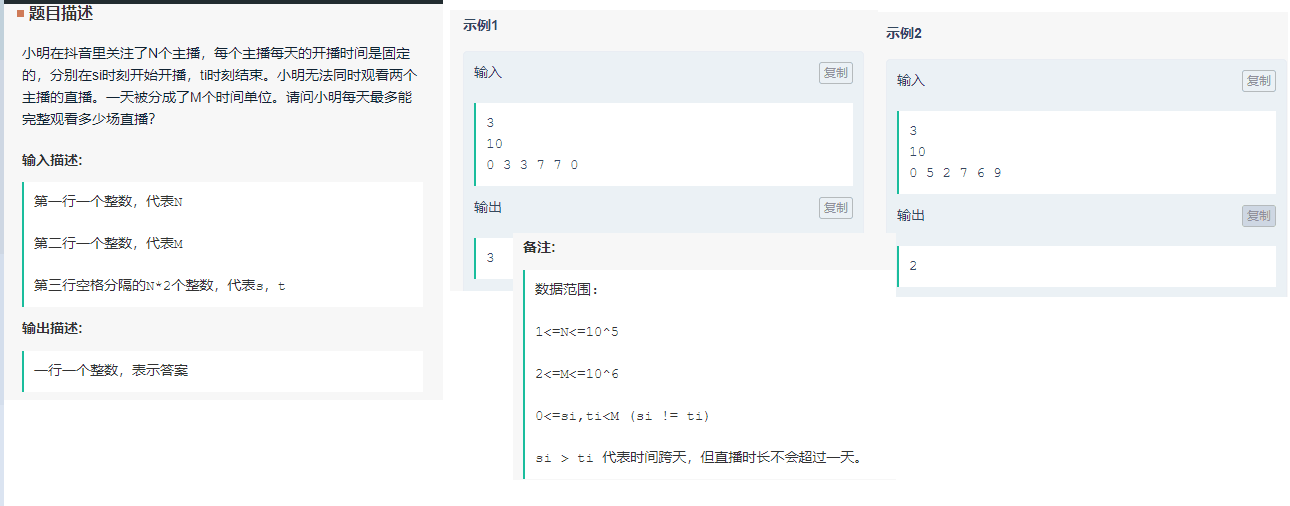
参考:经典的贪心算法
校招第二批笔试
2018.8.25 19校招第二批笔试
字节跳动大闯关
乔迁之喜,字节君决定邀请整个EE团队,举办一个大型团建游戏-字节跳动大闯关。
可是遇到了一个问题:
EE团队共有n个人,大家都比较害羞,不善于与陌生人交流。
这n个人每个人都向字节君提供了自己认识人的名字,不包括自己。
如果A的名单里有B,或B的名单里有A,则代表A与B相互认识。
同时如果A认识B,B认识C,则代表A与C也会很快认识,毕竟通过B的介 绍,两个人就可以很快相互认识的了。
为了大闯关游戏可以更好地团队协作、气氛更活跃,并使得团队中的人可以尽快的相互了解、认识和交流,字节君决定根据这个名单将团队分为m组,每组人数可以不同,但组内的任何一个人都与组内的其他所有人直接或间接的认识和交流。
如何确定一个方案,使得团队可以分成m组,并且这个m尽可能地小呢?
输入描述:第一行一个整数n,代表有n个人,从1开始编号。接下来有n行,第x+1行代表编号为x的人认识的人的编号k(1<=k<=n),每个人的名单以0代表结束。
输出描述:一个整数m,代表可以分的最小的组的个数。
示例
输入:
1 | 10 |
输出:
1 | 2 |
说明:
1号同学孤独地自己一个组,因为他谁也不认识,也没有人认识他。
其他所有人均可以直接或间接认识,分在同一个组。
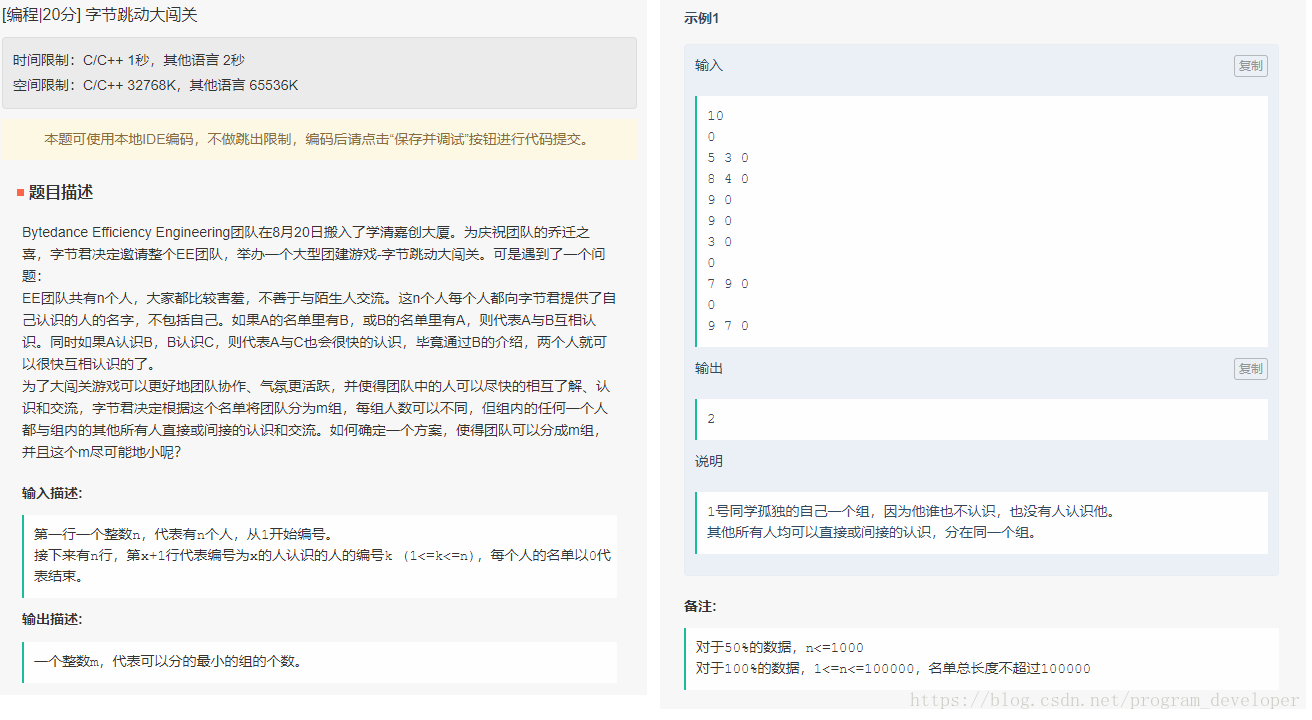
注意,题目意思是第一行10,代表一共有10个人,第二行0,代表编号为1的人不认识任何人,第三行0 5 3,代表编号为2的人认识编号5和编号3。
标准答案
该题与Leetcode547. 朋友圈思路一致,可以通过并查集快速解决。
代码
1 | import sys |
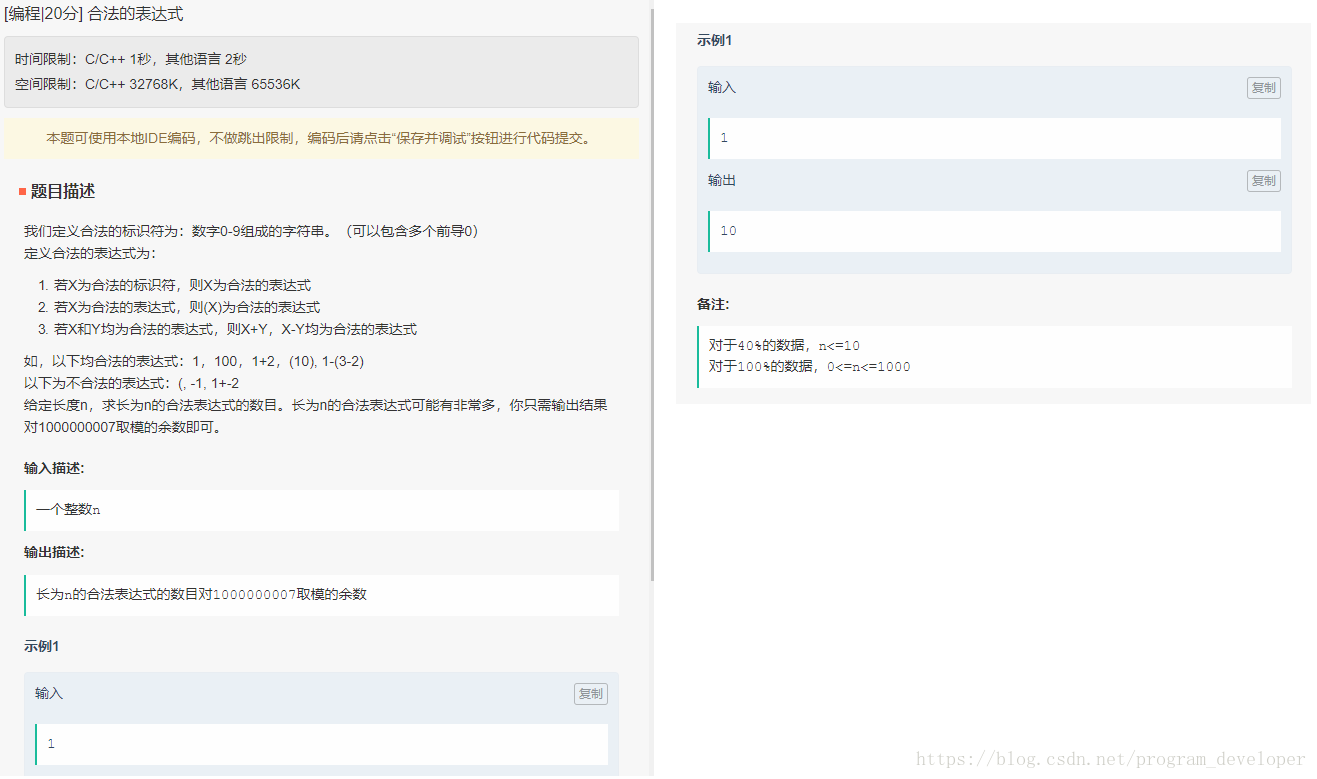
合法的表达式
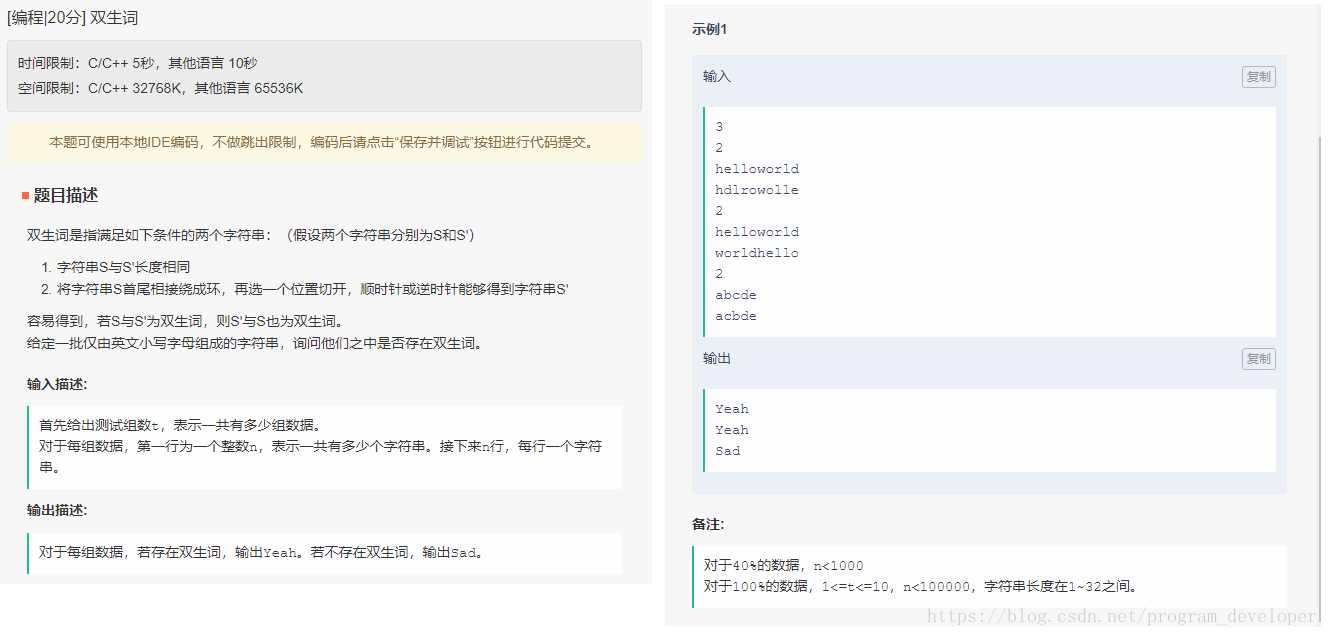
双生词
空气质量
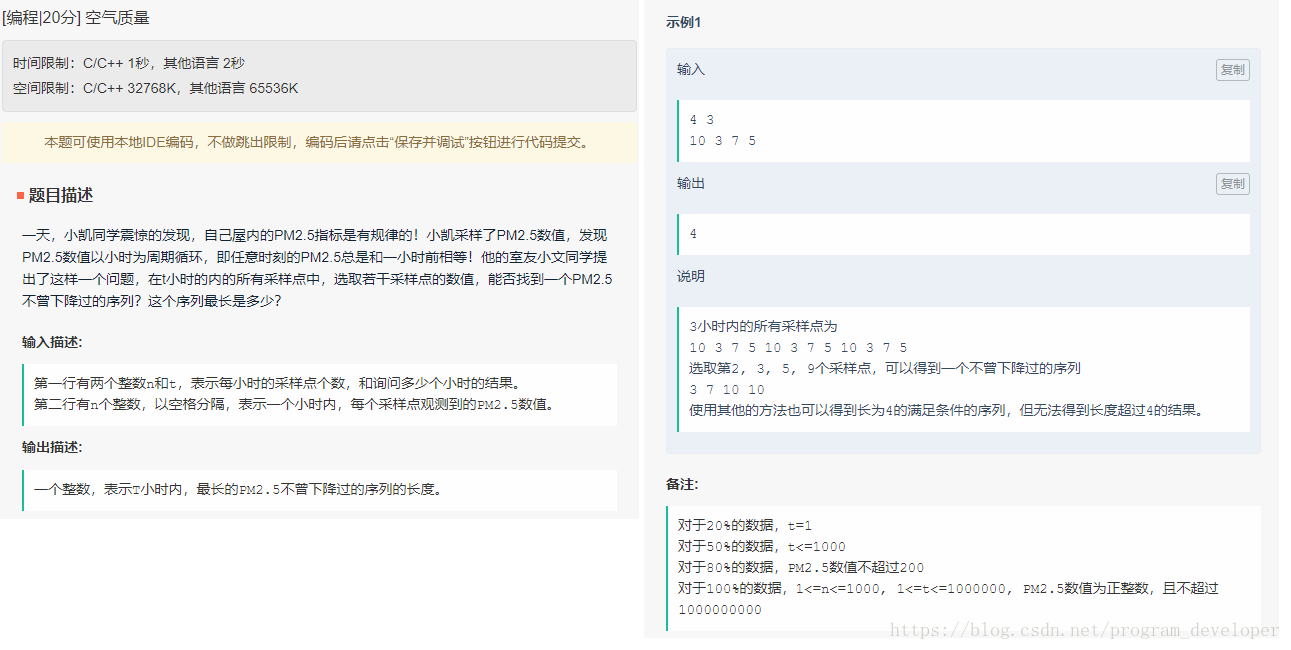
思路
和Leetcode300思路一样,这题是求最长不降子序列。
具体解题思路参考Leetcode300。
代码
1 | import sys |
参考:
leetcode300. 最长上升子序列
https://leetcode-cn.com/problems/longest-increasing-subsequence/
减法求值
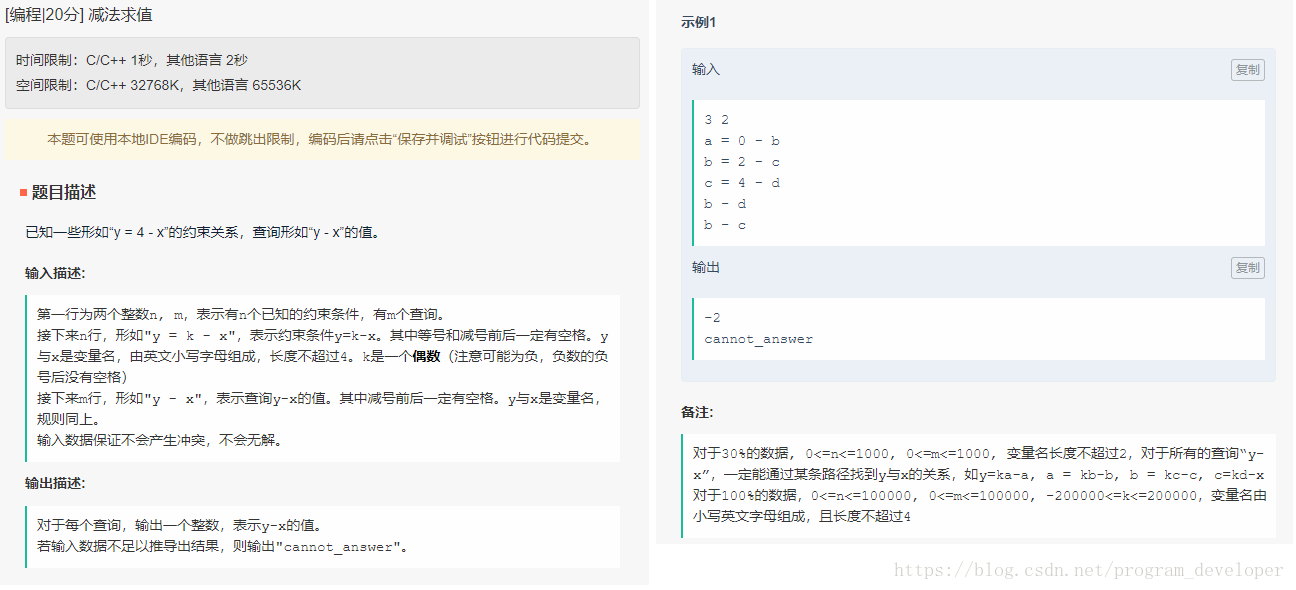
校招第三批笔试
2018.9.9 19校招第三批笔试
最大不重复子串
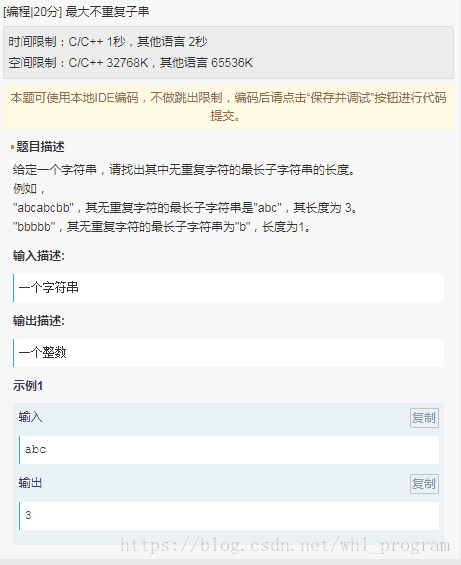
参考:
LeetCode 第3题原题
代码
1 | import sys |
组织优化
题目描述:
随着公司的快速发展,基层团队越来越多。近期公司希望对部门重新做一个划分,尽可能把紧密合作的团队放到同一个部门。
给定一个$M \times N$的2维数组,每个值1的元素代表一个团队。如果2个团队在上下或左右的方向上相邻,说明2个团队有紧密合作关系。
需要把合作紧密的团队放到一起,形成一个部门;没有合作关系的团队,放到不同部门。
判断给定输入中,有多少个部门。
例如,给定一个二维数组:
1 | 1 0 0 1 1 |
其中有9个团队,一共需要组成3个部门,分别是:
1 | 1 |
以及
1 | 1 1 |
以及
1 | 1 |
输入描述:
1 | 第一行一个整数,代表M |
输出描述:
1 | 一个整数,表示部门数量 |
示例1
1 | 输入 |
备注:
1 | 1 < M < 1000 |
参考:
岛屿问题,深度优先搜索,详细参考LeetCode 第200题
代码
1 | import sys |
IP还原
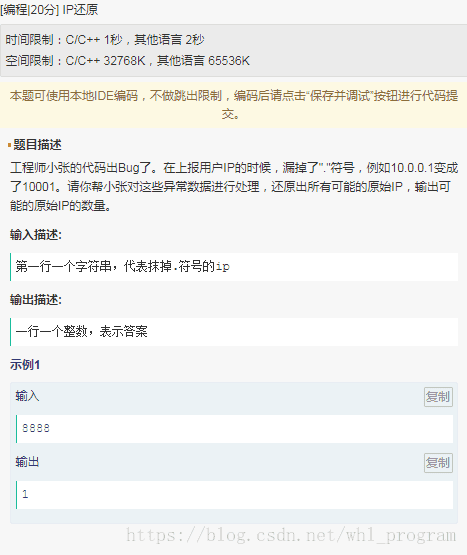
参考:
LeetCode 第93题
代码
1 | import sys |
注意:
代码中的res要注意。
UTF-8校验


参考:
LeetCode 第393题
代码
1 | import sys |
抖音红人

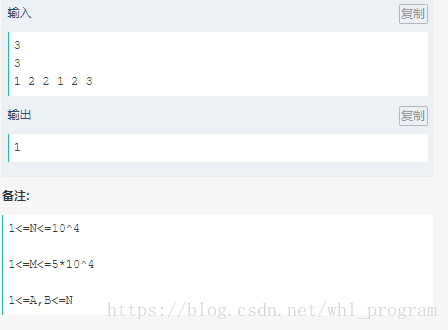
参考:
https://www.codetd.com/article/3148943
标准答案
遍历字典,并更新见解关注的关系
代码
1 | import collections |
奇虎360
2018.8.27 19校招第一批笔试
一共30道选择题,3道编程题。
选择题大多是C语言编程题,时间基本耗在这上面,导致根本没时间看编程题。网上也搜不到资源了。
招行信用卡
2018.8.30 19校招第一批笔试
都是选择题,着重考察机器学习相关知识。
上海农行研发软开
2018.9.1 19校招第一批笔试
题型包括行测、英语、计算机基础(重点考察数据库、C语言),还有最后的性格测试。
普华永道信息技术
2018.9.5 现场全英文笔试
数学、python、机器学习、图像识别、openCV、文本NLP、RNN、正则。
美团
2018.9.6 19校招第一批笔试
选择题:考察行测、机器学习、计算机基础、高数
编程题:
1.大富翁游戏
题目描述:
大富翁游戏,玩家根据骰子的点数决定走的步数,即骰子点数为1时可以走一步,点数为2时可以走两步,点数为n时可以走n步。
求玩家走到第n步(n<=骰子最大点数且是方法的唯一入参)时,总共有多少种投骰子的方法。
输入描述:
输入包括一个整数n,(1 ≤ n ≤ 6)
输出描述:
输出一个整数,表示投骰子的方法
输入例子1:
1 | 6 |
输出例子1:
1 | 32 |
标准代码
和爬楼的想法类似,走n步可以想下除了最后一步以外有几种情况。
参考Leetcode70.爬楼梯
代码
1 | import sys |
2.拼凑钱币
题目描述:
给你六种面额 1、5、10、20、50、100 元的纸币,假设每种币值的数量都足够多,编写程序求组成N元(N为0~10000的非负整数)的不同组合的个数。
输入描述:
输入包括一个整数n(1 ≤ n ≤ 10000)
输出描述:
输出一个整数,表示不同的组合方案数
输入例子1:
1 | 1 |
输出例子1:
1 | 1 |
B站
2018.9.7 19校招第一批笔试
比较两个版本字符串version1和version2
题目描述:
如果version1 > version2 返回1,如果version1 < version2 返回-1,不然返回0
输入的version字符串非空,只包含数字和字符。字符不代表通常意义上的小数点,只是用来区分数字序列。例如字符串2.5并不代表二点五,只是代表版本是第一级别是2,第二级别是5.
输入:
两个字符串,用空格分割
每个字符串为一个version字符串,非空,只包含数字和字符。
输出:
只能输出1,-1,或0
样例输入:
1 | 0.1 1.1 |
样例输出:
1 | 1 |
顺时针打印数字矩阵
题目描述:
给定一个数字矩阵,请设计一个算法从左上角开始顺时针打印矩阵元素
输入:
第一行是两个数字,分别代表行数M和列数N;接下来是M行,每行N个数字,表示这个矩阵的所有元素;当读到M=-1,N=-1时,输入终止。
输出:
请按逗号分割顺时针打印矩阵元素(注意最后一个元素末尾不要有逗号!例如输出“1,2,3”,而不是“1,2,3,”)每个矩阵输出完成后记得还行;
样例输入:
1 | 3 3 |
样例输出:
1 | 1,2,3,6,9,8,7,4,5 |
精灵鼠从入口到出口的最少减速
题目描述:
猛兽侠中精灵鼠在利剑飞船的追逐下逃到一个n*n的建筑群中,精灵鼠从(0,0)的位置进入建筑群,建筑群的出口位置为(n-1,n-1),建筑群的每个位置都有阻碍,每个位置上都会相当于给了精灵鼠一个固定值减速,因为精灵鼠正在逃命所以不能回头只能向前或者向下逃跑,现在精灵鼠最少在减速多少的情况下逃出迷宫?
输入:
第一行迷宫的大小:n>=2 & n <= 10000;第2到n+1行,每行输入为以‘,’分割的该位置的减速,减速 f >= 1 & f < 10。
输出:
精灵鼠从入口到出口的最少减少速度?
样例输入:
1 | 3 |
样例输出:
1 | 19 |
商汤科技
2018.9.7 19校招第一批笔试
最小极差
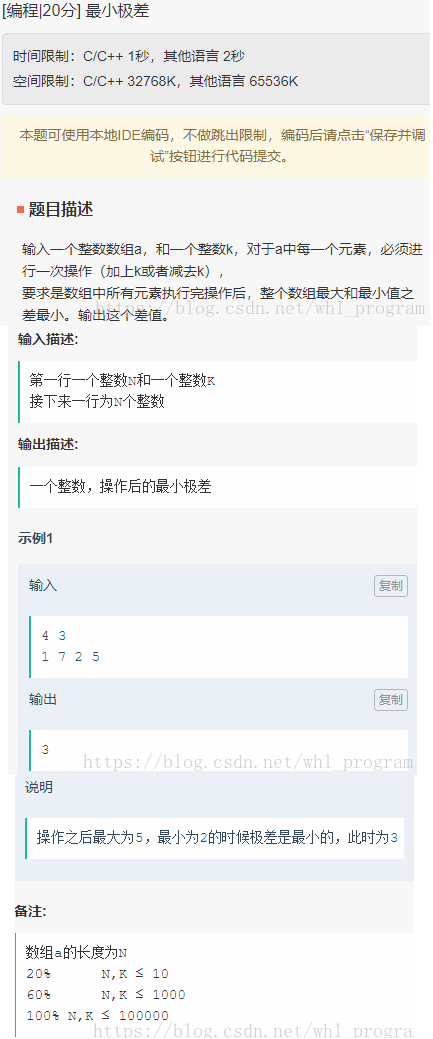
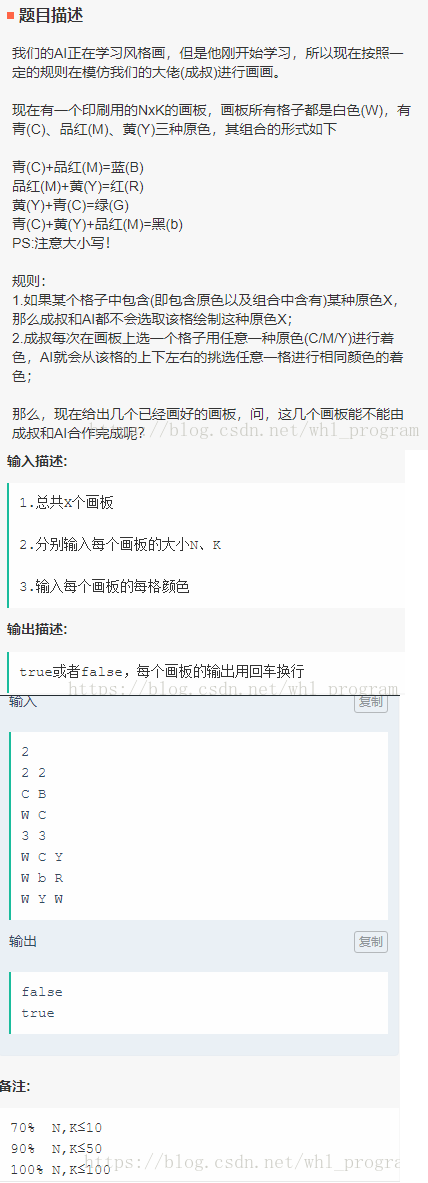
三原色画板
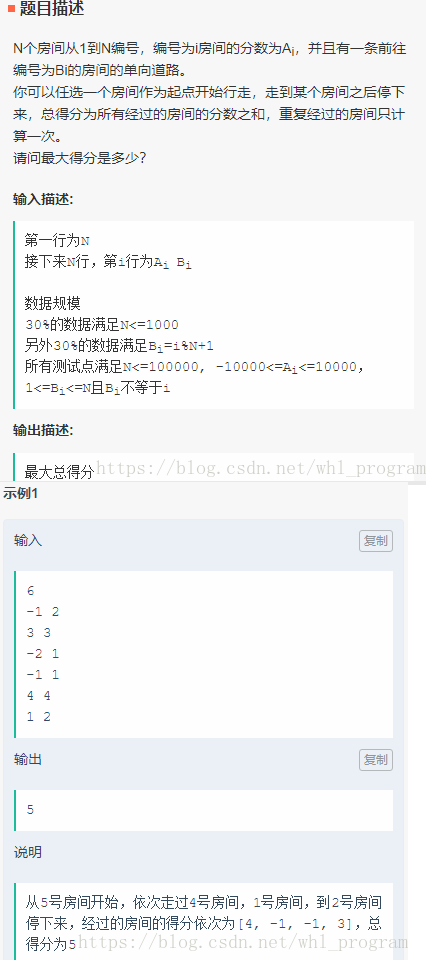
房间
巨人网络
2018.9.7 19校招第一批笔试
编程题竟然都是SQL语句。
第四范式
2018.9.9 19校招建模工程师笔试
流水表中插入切片表数据

数组分解K个等和子数组

京东
2018.9.9 19校招数据分析工程师笔试
完全多部图

相似子字符串

中国电信IT研发
2018.9.10 19校招大数据工程师
题型分为单选、多选以及编程题,题目大部分是牛客网原题,提前30min交卷😏
迅雷
2018.9.12 19校招大数据分析工程师
全部都是选择题,重点考察概率、数据库以及大数据相关工具Hadoop,Hive等。
记录开发岗两道开发岗的编程题。
红黑积木求和

素勾股数

小米
2018.9.27 19校招算法工程师
10道单选,10道专业多选,2道编程题
厨艺大赛奖金


扑克牌四则运算


牛客网2019年第一次模拟笔试
独立的牛牛
状态:通过40%
题目:
小牛牛为了向他的父母表现他已经长大独立了,他决定搬出去自己居住一段时间。
一个人生活增加了许多花费: 牛牛每天必须吃一个水果并且需要每天支付x元的房屋租金。
当前牛牛手中已经有f个水果和d元钱,牛牛也能去商店购买一些水果,商店每个水果售卖p元。
牛牛为了表现他独立生活的能力,希望能独立生活的时间越长越好,牛牛希望你来帮他计算一下他最多能独立生活多少天。
输入描述:
输入包括一行,四个整数x, f, d, p(1 <= x,f,d,p <= 2 * 10^9),以空格分割
输出描述:
输出一个整数, 表示牛牛最多能独立生活多少天。
示例1
输入
3 5 100 10
输出
11
牛牛炒股票
状态:不会
题目:
牛牛得知了一些股票今天买入的价格和明天卖出的价格,他找犇犇老师借了一笔钱,现在他想知道他最多能赚多少钱。
输入描述:
每个输入包含一个测试用例。
输入的第一行包括两个正整数,表示股票的种数N (1<=N<=1000)(1<=N<=1000)和牛牛借的钱数M (1<=M<=1000)(1<=M<=1000)。
接下来N行,每行包含两个正整数,表示这只股票每一股的买入价X (1<=X<=1000)(1<=X<=1000) 和卖出价Y (1<=Y<=2000)(1<=Y<=2000)。
每只股票可以买入多股,但必须是整数。
输出描述:
输出一个整数表示牛牛最多能赚的钱数。
样例:
输入:
3 5
3 6
2 3
1 1
输出:
4
牛牛取快递
状态:
题目:
牛牛的快递到了,他迫不及待地想去取快递,但是天气太热了,以至于牛牛不想在烈日下多走一步。他找来了你,请你帮他规划一下,他最少要走多少距离才能取回快递。
输入描述:
每个输入包含一个测试用例。
输入的第一行包括四个正整数,表示位置个数N(2<=N<=10000),道路条数M(1<=M<=100000),起点位置编号S(1<=S<=N)和快递位置编号T(1<=T<=N)。位置编号从1到N,道路是单向的。数据保证S≠T,保证至少存在一个方案可以从起点位置出发到达快递位置再返回起点位置。
接下来M行,每行包含三个正整数,表示当前道路的起始位置的编号U(1<=U<=N),当前道路通往的位置的编号V(1<=V<=N)和当前道路的距离D(1<=D<=1000)。
输出描述:
对于每个用例,在单独的一行中输出从起点出发抵达快递位置再返回起点的最短距离。
示例1
输入
3 3 1 3
1 2 3
2 3 3
3 1 1
输出
7